Code LLMs hallucinate function names, file paths, and class hierarchies all the time. Not because they can’t write code, but because they don’t know what exists in other files.
I spent a few weeks running controlled experiments to figure out why, measure it, and see how little information you actually need to fix it. This is the full journey, including the stuff that didn’t work.
The Setup
- Model: Gemma 4 E4B-it (4B params, bf16)
- Hardware: Dual RTX 4090, AMD Threadripper, 256GB RAM
- Test project: 3-file Python task management system with cross-file dependencies
The project has models.py for domain objects, repository.py for data access, and service.py for business logic. It’s small on purpose. Every function in service.py depends on types and methods from the other two files.
To complete something like get_user_workload(), the model needs to know that TaskRepository has a get_tasks_by_assignee() method, that TaskStatus.IN_PROGRESS exists, and that Task has an is_blocked property. None of that shows up in the function signature.
The First Clue: SWE-bench Lite
Before building the controlled experiments, I tested on 20 instances from SWE-bench Lite (real GitHub issues from astropy, django, and others) to see if navigation was even a bottleneck worth studying.
Same model (Gemma 4 E4B-it, bf16, single 4090). Three conditions:
- Problem only: the issue description + repo name, prompted to generate a unified diff patch. No hints about where to look.
- Problem + hints: same prompt, but with SWE-bench’s own
hints_textfield appended (a natural-language description of the bug’s location). - File oracle: ground-truth file paths from the reference patch prepended as a “Files to modify” section. This simulates what you’d get from LSP “go to definition” — just the paths, no file contents.
I measured GF F1 (Git-File F1): extract file paths from both the generated and reference diffs, then compute precision/recall/F1 on the file sets. It answers one question: did the model edit the right files?
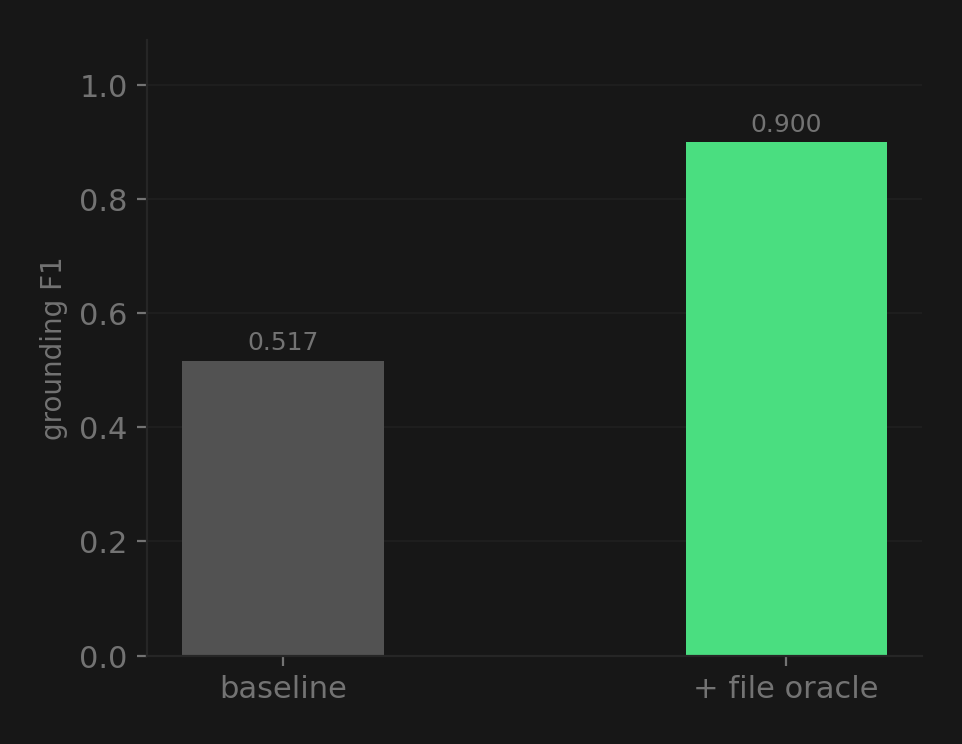
| Condition | GF F1 |
|---|---|
| Problem only | 0.517 |
| Problem + hints | 0.524 |
| File oracle | 0.900 |
The natural-language hints barely moved the needle (0.517 → 0.524). But giving the model the actual file paths — just the names, no contents — jumped accuracy to 0.900. The model went from editing the wrong files half the time to getting it right 90% of the time, from a few tokens of path strings.
This is what motivated the controlled experiments below. If file-level navigation is this much of a bottleneck on real issues, how little context do you actually need to fix it?
Experiment 1: Does LSP Context Help?
I tested 6 functions with two conditions each:
- Naked: just the function signature, nothing about other files
- LSP prefix: a short text block listing cross-file symbols with their types and locations
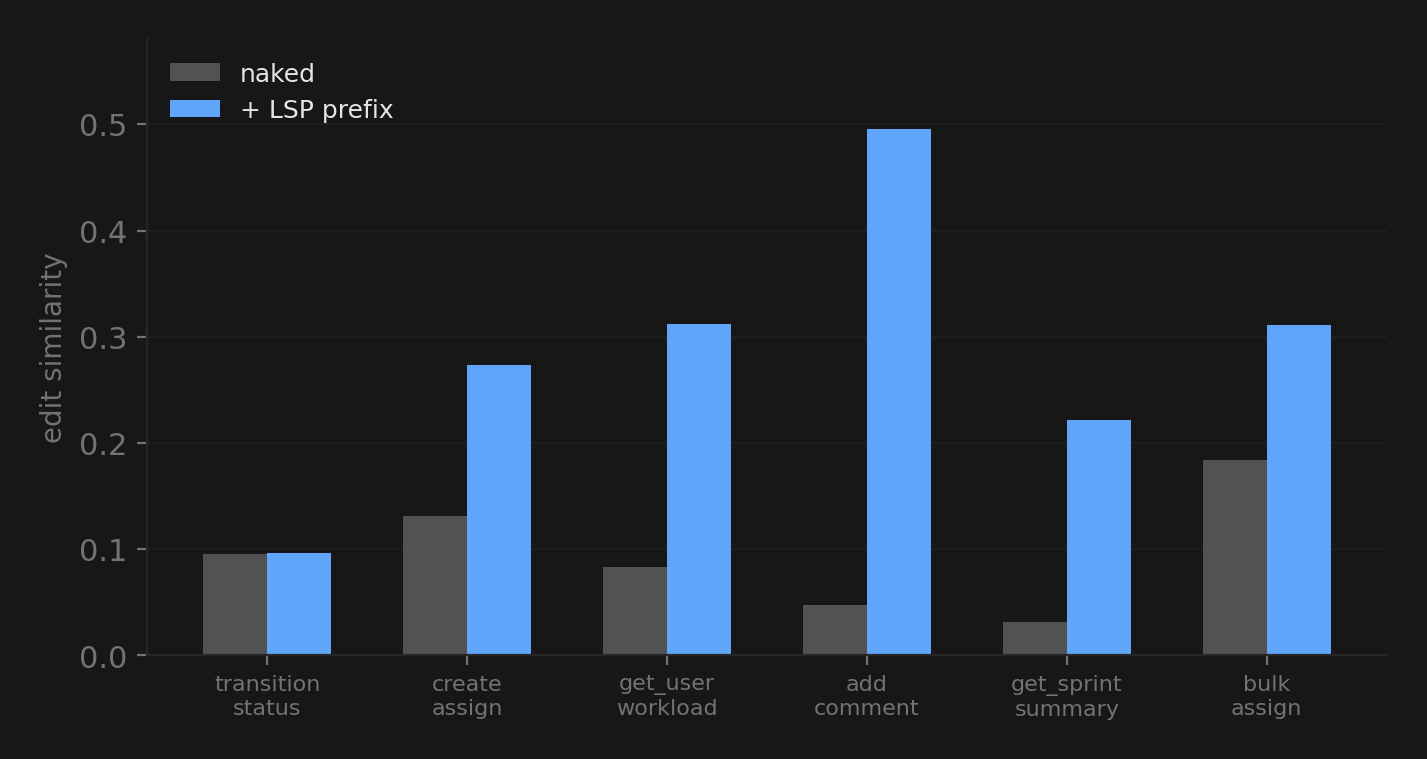
The biggest wins were on functions that depend heavily on other files. add_comment() went from 0.047 to 0.496. Without context, the model just made up self.repo.add_comment() which doesn’t exist anywhere. With the LSP prefix, it correctly built a Comment object using the constructor args from models.py.
Symbol recall (the % of correct cross-file symbols the model actually references) went from 0.583 to 0.833.
Experiment 2: How Little Context Do You Need?
This is where it gets interesting. I tested 5 levels of detail, from nothing to full type signatures:
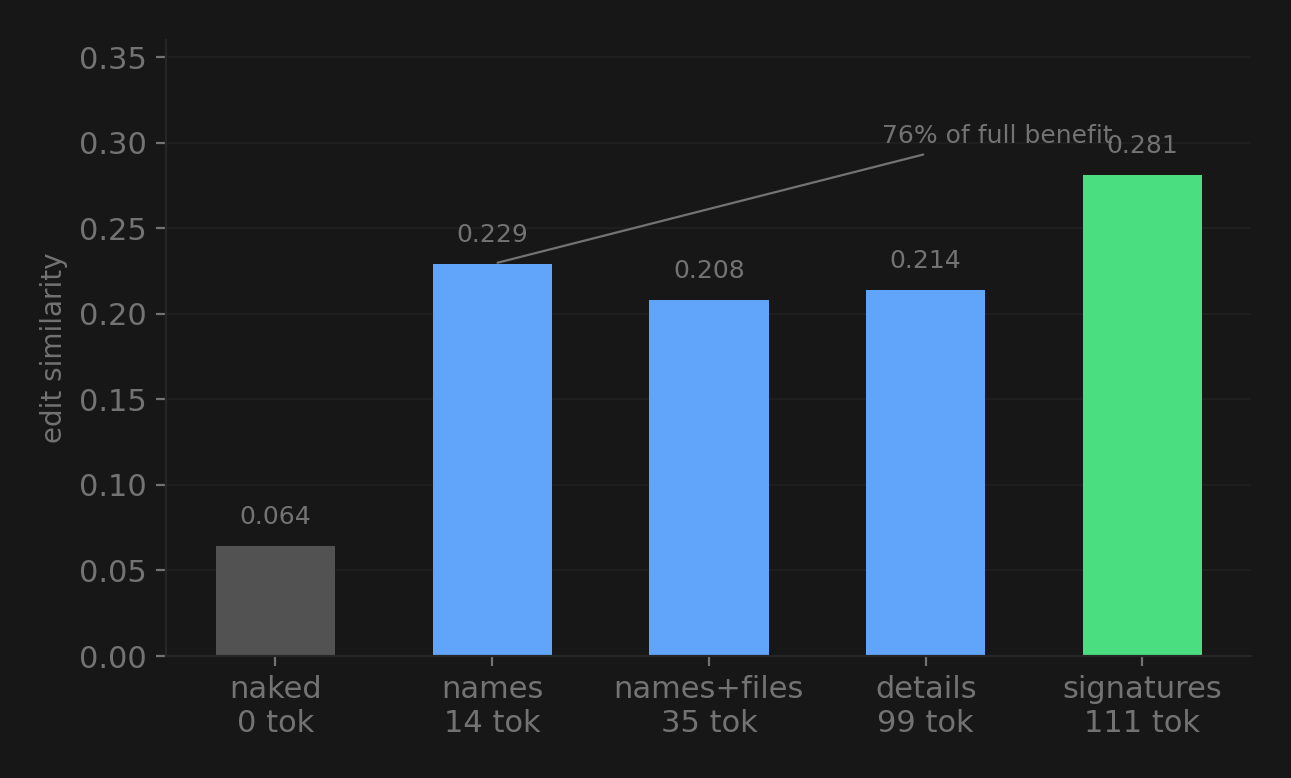
14 tokens of symbol names captured 76% of the benefit. The model mostly just needs to know what exists. Adding file locations, type details, and full signatures helps, but the first 14 tokens do most of the heavy lifting.
The model doesn’t need to know that get_tasks_by_assignee() takes a User and returns list[Task]. It can figure that out from the name. It just needs to know the method is there.
Experiment 3: Full Files vs LSP Prefix
This is where my thesis got challenged.
I added a condition where the model gets all 3 source files pasted in as context (2,444 tokens). Then I tried something else. I took the KV cache states the model builds when it processes those files and transplanted them into a naked prompt. No text tokens at all, just the internal representation.
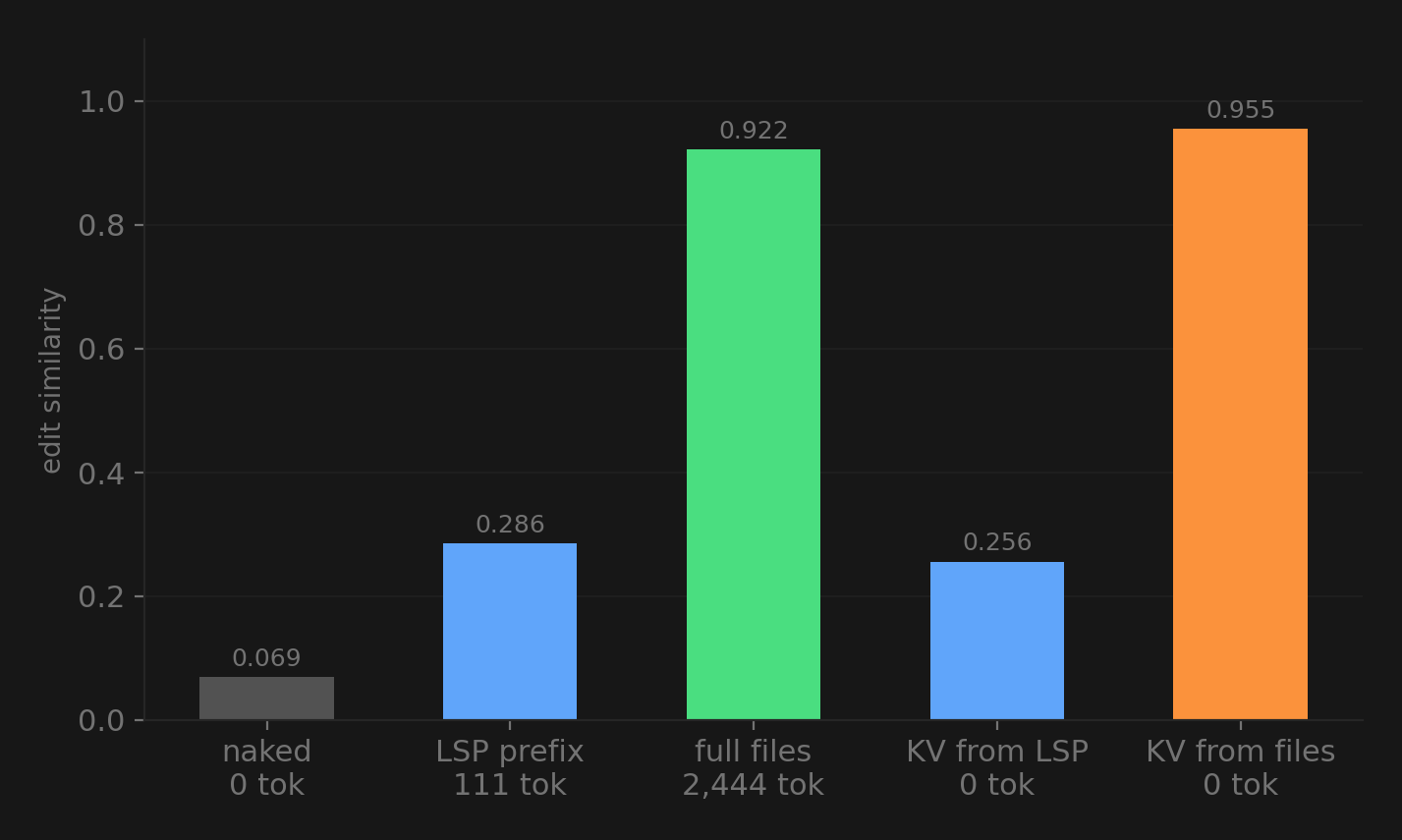
Three things jumped out:
The LSP prefix only captures 25% of the full-files benefit (0.286 vs 0.922). The model doesn’t just need to know what exists, it needs to see the actual implementations. Knowing that TaskRepository.get_task() exists is useful, but seeing that it does self._tasks.get(task_id) and understanding the patterns and variable names is what gets you to 92%.
The KV transplant from full files beat the actual full files (0.955 vs 0.922) with zero text tokens. Two functions hit perfect 1.000 edit similarity. The model’s internal representation of the project context is not just reusable, it’s slightly more effective when you inject it directly.
This is basically prompt caching. What I measured here is essentially what Anthropic, Google, and OpenAI already ship as a product. The contribution isn’t the mechanism, it’s the measurement. How much does it actually matter for cross-file code context specifically?
The Failed Encoder
Before these experiments, I spent time training a learned encoder. The idea was to compress LSP features into 4 virtual token embeddings and inject them into the model. A 2.5M parameter network that takes a 32x112 feature tensor from LSP symbols and outputs 4 embeddings in the model’s hidden space.
It didn’t work.
The encoder converged during training (loss went from 1.58 to 1.08 over 20 epochs on 553 functions from 5 real Python repos). But at inference, the embeddings it produced were no better than random noise:
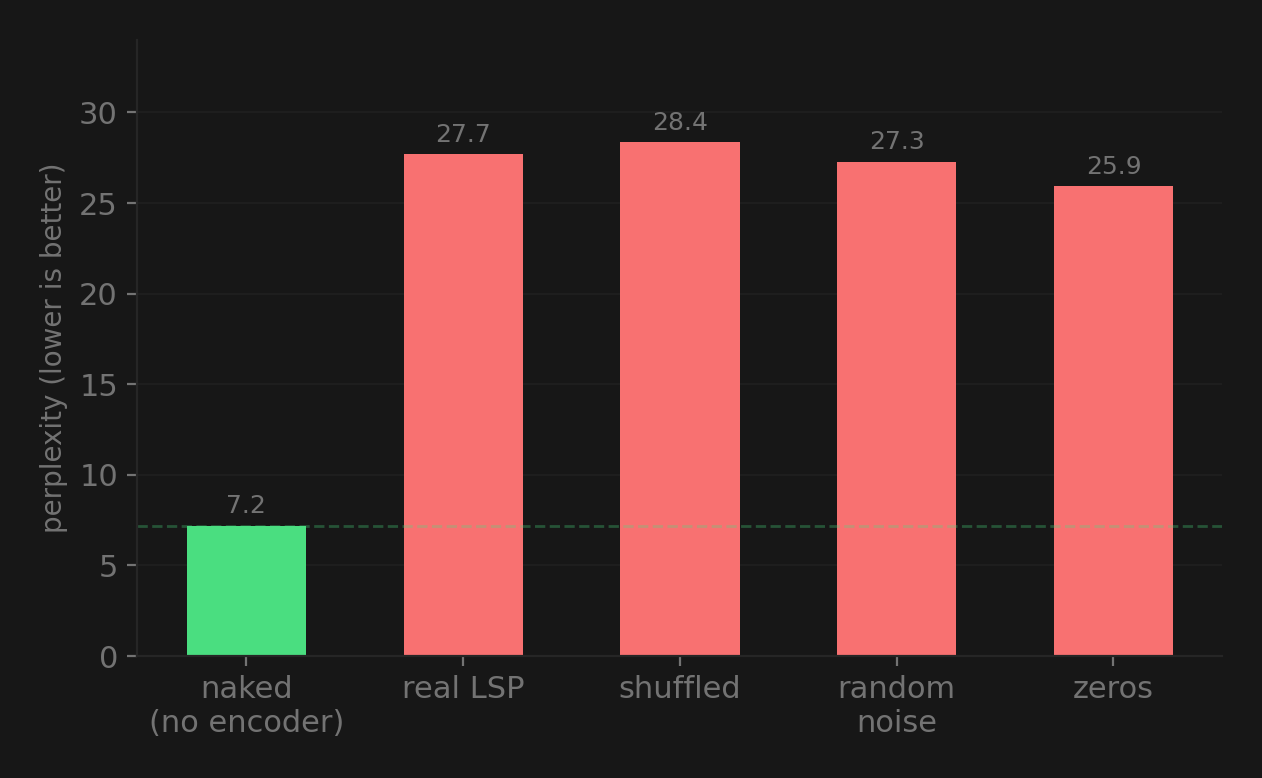
Every encoder condition made things worse than no encoder at all. Real features, shuffled features, random noise, all zeros. All roughly the same. The encoder memorized the training loss without learning anything generalizable.
I also found a gradient bug halfway through. The original training code used .data assignment to write embeddings into the vocabulary table, which silently bypasses autograd. Gradients never actually flowed back to the encoder. I fixed it with a forward hook, got real gradients going (grad_norm ~1.5), loss dropped further. But the core problem didn’t go away. 553 samples and 2.5M parameters just isn’t enough for this kind of compression.
The KV transplant experiment later showed why it failed. The model’s internal representation of full-file context is rich and high-dimensional. Trying to approximate that with 4 learned tokens from a feature summary is like trying to describe a painting with 4 numbers.
What I Learned
Navigation matters more than comprehension. On SWE-bench, file paths alone jumped accuracy from 0.517 to 0.900. The model knows how to write Python. It just doesn’t know what’s in your other files. That’s the gap.
The minimum signal is surprisingly small. 14 tokens of symbol names gets you 76% of the way. But LSP summaries alone aren’t enough for really good completions, you still need actual code. The practical takeaway: use LSP to pick which files go in the context window, don’t use it as a replacement for the files themselves.
Context window budgeting matters. If you have 4K tokens of budget (pretty common for local models), the question isn’t “how do I compress everything?” It’s “which files do I load?” LSP answers that.
Learned compression is hard. The gap between copying real KV states (works great) and generating equivalent states from features (fails completely) is huge. Probably needs way more data and parameters than what I threw at it.
Negative results are results. The encoder failing pushed me toward the compression curve and KV transplant experiments, which ended up telling a much clearer story.
Built on a 4090 with a rented A100 for the encoder training. Total compute cost: about $20.